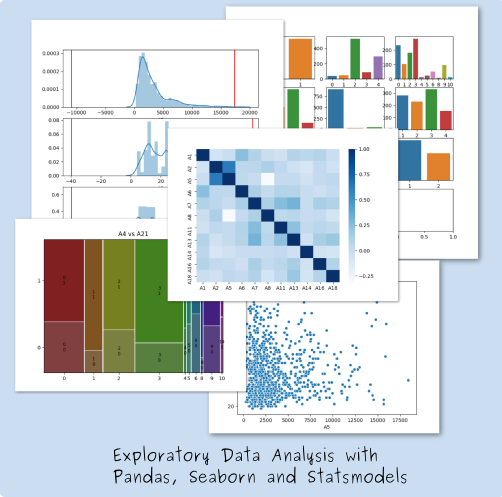
Summary:
This course is a CrashProgram (short course) introducing exploratory data analysis. The course is at an introductory technical level. It requires some familiarity with credit risk data (and an ability to open and inspect data files). Step by step we build the knowledge required to perform a comprehensive exploratory data analysis
Prerequisites:
The course can be pursued on a standalone basis. It is advisable to pursue the course after DAT31046 (Risk Data Review) which discusses a review of the data from a data quality validation perspective.
Outcomes:
- We learn the concept and techniques of Exploratory Data Analysis
- Touch upon the issue of bias and how to mitigate it
- Learn about more advanced formats such as HDF
- Basic exploratory analysis using pandas
- Easy visual analysis of association using seaborn
- Contingency tables, WoE and Information Value using pandas, scipy and statsmodels
- We summarize our findings in terms of numerical and graphical results in a mock report written in Markdown format
Course Level and Type:
| Introductory Level | Core Level | Advanced Level | |
| Non-Technical | |||
| Technical | CrashProgram DAT31048 |
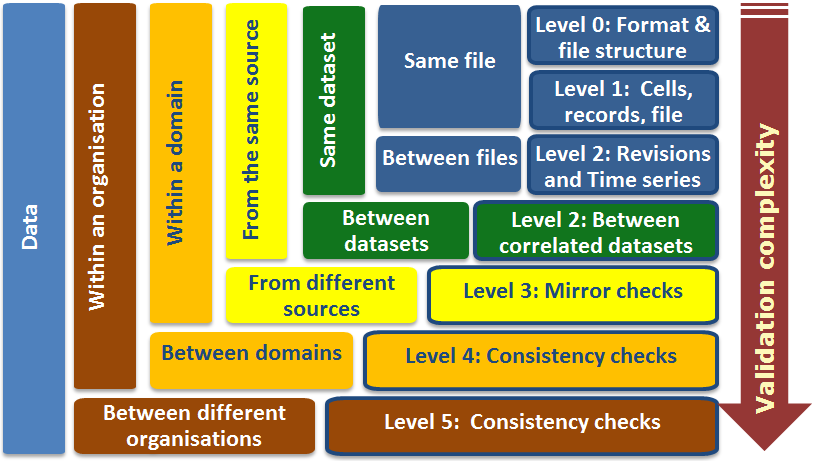
Summary:
This course is a CrashProgram (short course) introducing the concept of a structured review of risk data. The course is at an introductory technical level. It requires some familiarity with credit risk data (and an ability to open and inspect data files) Step by step we build the knowledge required to review the suitability of data for a given purpose and how to report the findings
Outcomes:
- We learn the concept of Data Provenance
- We get a first exposure to the different levels of Data Validation as recommended by EuroStat
- We summarize our findings in a mock report written in Markdown format
Course Level and Type:
| Introductory Level | Core Level | Advanced Level | |
| Non-Technical | |||
| Technical | CrashProgram DAT31046 |
Summary
Visualization of Timeseries Data
Course Level and Type:
| Introductory Level | Core Level | Advanced Level | |
| Non-Technical | |||
| Technical | DAT31056 |
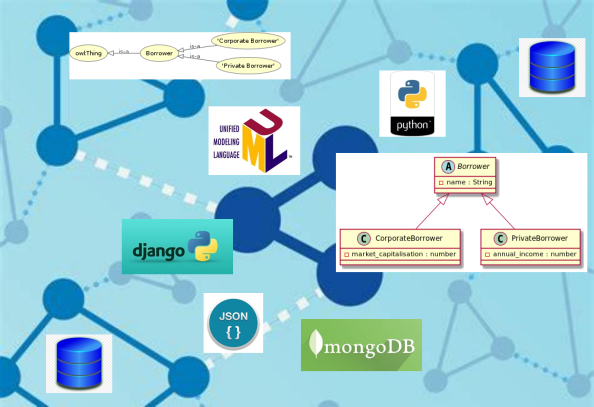
This course is a CrashProgram (short course) that explores how class inheritance of related data objects can be handled in a data science context. The course is at a core technical level. It requires some familiarity with database models, data specifications such as JSON and a basic knowledge of Python.
Course Level and Type:
| Introductory Level | Core Level | Advanced Level | |
| Non-Technical | |||
| Technical | CrashProgram DAT31063 |

Summary:
An overview of graph methods in data sciences
Course Level and Type:
| Introductory Level | Core Level | Advanced Level | |
| Non-Technical | |||
| Technical |
Summary:
In this course we do an in-depth comparison of the Linear Algebra functionalities offered by the open source numerical libraries Numpy, Eigen and Armadillo.
The focus of the course is mathematical functionality, not performance or other technical deployment aspects.
Course Level and Type:
| Introductory Level | Core Level | Advanced Level | |
| Non-Technical | |||
| Technical | DAT 31055 |